The pattern
Most Fusion HCM integration feeds we audit use a variant of this:
SELECT ...
FROM PER_ALL_ASSIGNMENTS_M paf
WHERE paf.LAST_UPDATE_DATE > SYSDATE - (:p_hours / 24)
AND paf.PRIMARY_FLAG = 'Y'
AND paf.EFFECTIVE_LATEST_CHANGE = 'Y'
AND paf.ASSIGNMENT_STATUS_TYPE = 'ACTIVE'It looks clean. It runs fast on test data. And it breaks in three specific ways the moment it goes live against a real workforce.
The three side-effects at a glance
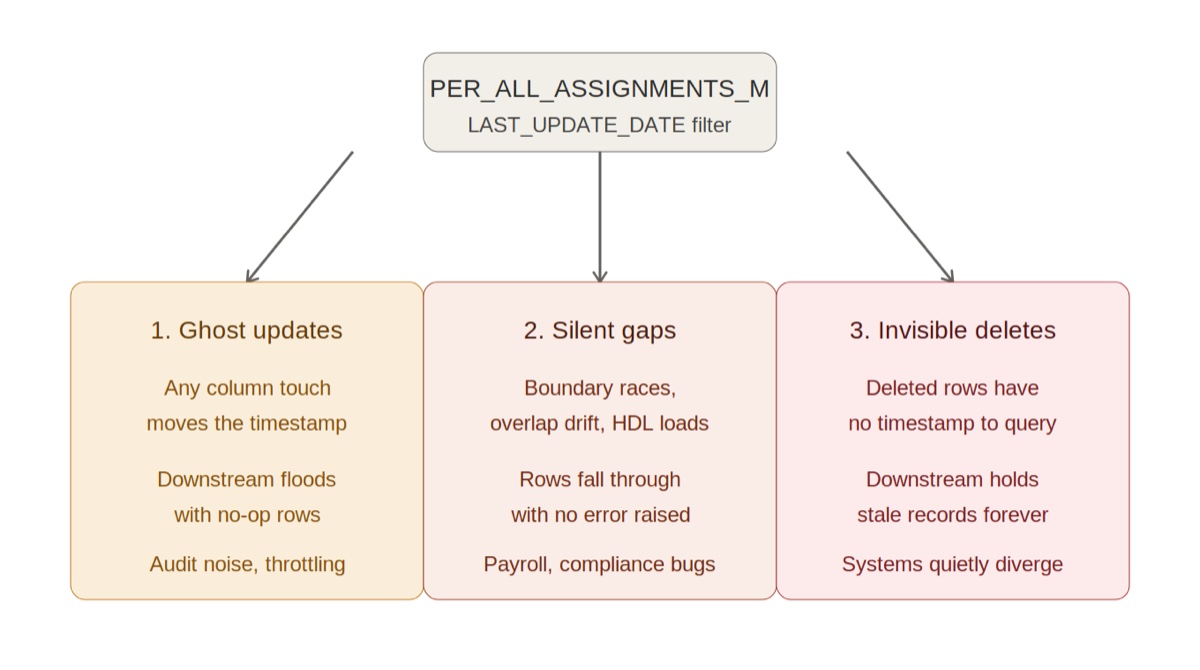
| Side-effect | Symptom | Root cause | Business impact |
|---|---|---|---|
| 1. Ghost updates | Downstream floods with identical rows | LAST_UPDATE_DATE moves on any column touch, including Fusion background jobs | Audit noise, throttled feeds, wasted BAU cycles |
| 2. Silent gaps | Rows missing downstream with no error raised | Boundary races, run-overlap drift, bulk loads on the filter edge | Payroll errors, compliance access gaps surfacing weeks later |
| 3. Invisible deletes | Stale records persist downstream forever | Deleted or end-dated rows have no timestamp to query | Two systems quietly diverge until a business process breaks |
1. Ghost updates
What happens:
- LAST_UPDATE_DATE moves on every column change, not just business-relevant ones
- Fusion background jobs (security profile recomputation, person-search indexing) update rows too
- DFFs, working hours flags, and assignment metadata trigger the same filter
Result: your downstream consumer receives a row identical to the last one it processed. Multiply by thousands of employees and dozens of background touches per day.
Symptoms in BAU:
- Audit logs full of no-op transactions
- Feeds throttling under volume that no real business change explains
- Support tickets investigating "changes" where no business field moved
2. Silent gaps
What happens: SYSDATE - (:p_hours / 24) is a sliding window calculated at execution time. Three concrete failure modes:
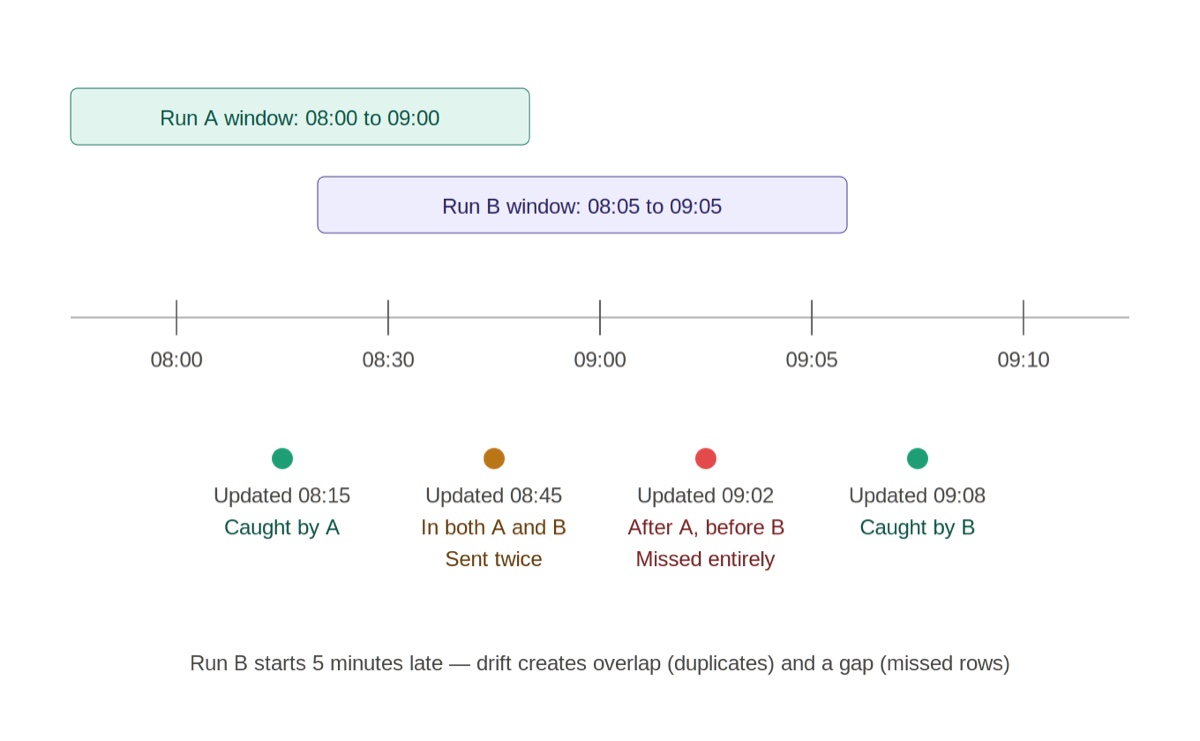
- Boundary races. Rows updated at exactly the cutoff timestamp get double-counted or skipped depending on whether you used > or >=.
- Run-overlap drift. A 5-minute drift in job start time means some rows are processed twice and others are missed entirely. You’re trusting wall-clock scheduling to be perfect, which it isn’t.
- Bulk load timing. HDL loads writing thousands of rows in a narrow window can straddle your filter boundary, splitting an atomic load across two batches or dropping the overlap.
Why this is the worst of the three: every one of these is valid SQL. No error is raised. No alert fires. The discrepancy surfaces weeks later as a payroll error or compliance gap.
3. Invisible deletes
What happens:
- An assignment is end-dated, or an absence record is hard-deleted
- EFFECTIVE_LATEST_CHANGE = 'Y' shifts to a new slice when a future-dated change is created — the old slice still exists but no longer matches the filter
- A deleted row has no LAST_UPDATE_DATE to query
Result: the downstream system holds the stale record forever. The two systems quietly diverge until a business process collides with the inconsistency — usually payroll, access provisioning, or audit.
Why the fix is not at the report layer
When these issues surface, the instinct is to patch the data model. Don’t.
What teams try:
- Analytic functions to compute deltas inside the BIP query
- Correlated subqueries to detect missing rows
- PL/SQL wrappers to handle edge cases
Why it fails:
- Fusion BIP runs under query timeouts and output-size limits
- BIP is not built for heavy joins or window functions across millions of rows
- Forcing BIP to be an ETL tool produces timeout errors blamed on "the report" when the problem is architectural
The fix belongs at the data architecture level, not the reporting layer.
Before vs after
A direct comparison of what changes when you move off the timestamp pattern:
| Dimension | Old: timestamp-based BIP | New: HCM Extract or OIC |
|---|---|---|
| Delta detection | LAST_UPDATE_DATE > :last_run | Change-tracking metadata or hash-compare |
| Ghost updates | Frequent — every column touch fires | Eliminated — only relevant fields trigger |
| Silent gaps | Likely — boundary races and drift | Deterministic — no time-window dependency |
| Delete detection | Impossible — no row, no timestamp | Native — disappearance is an explicit event |
| Where logic lives | Inside BIP data model (wrong layer) | Data layer (Extract) or PaaS (OIC) |
| Failure mode | Silent — surfaces weeks later | Loud — explicit events with old/new values |
| BAU support cost | High — phantom tickets, manual reconciliations | Low — feeds only carry real changes |
The two cloud-native pathways
Two distinct fixes. Choose based on where the downstream system sits and how much transformation it needs.
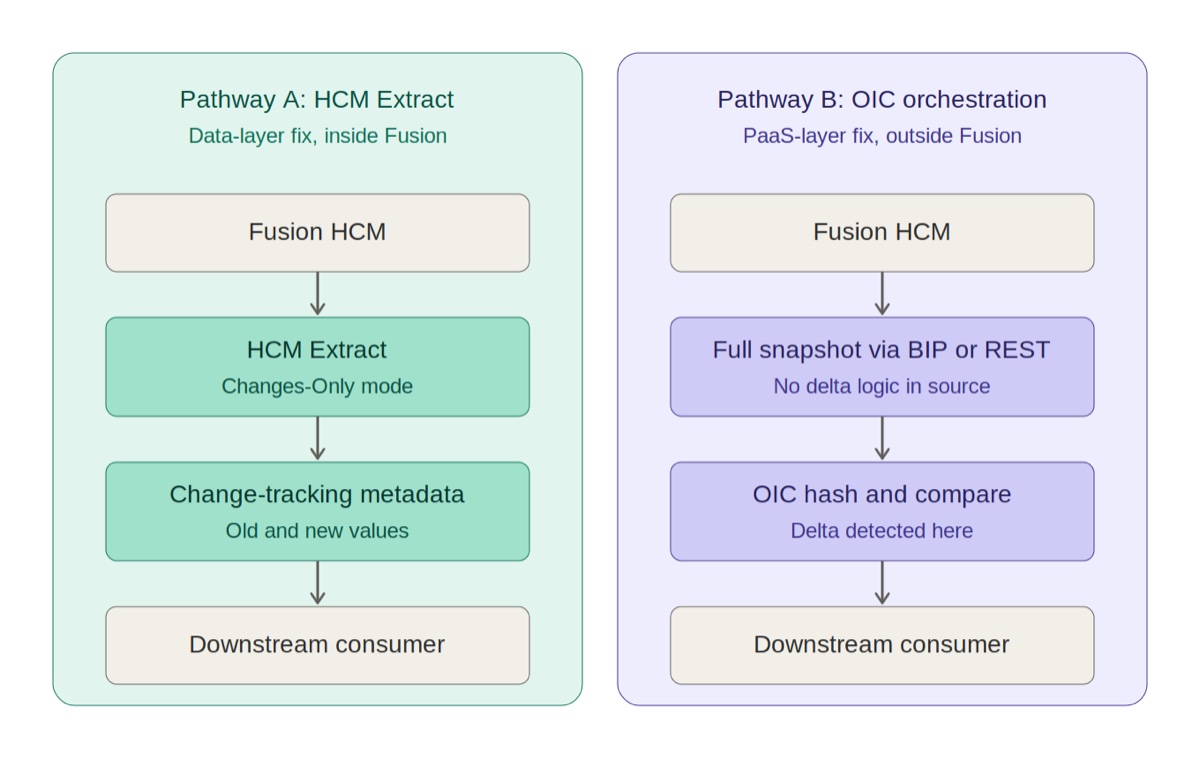
| Dimension | Pathway A: HCM Extract | Pathway B: OIC orchestration |
|---|---|---|
| Layer | Data layer, inside Fusion | PaaS layer, outside Fusion |
| Mechanism | Native Changes-Only change tracking | Snapshot + hash + compare in OIC |
| Output format | XML, CSV, or custom eText templates | Any payload OIC can construct |
| Transformation | Modest — template-bound | Custom — full programmability |
| Auditability | Inside Fusion, fully native | OIC monitoring, OCI logs |
| Best for | Payroll, identity, statutory feeds where you control the consumer contract | Legacy or third-party SaaS consumers needing custom payloads or enrichment |
| Avoid when | Downstream contract is highly bespoke | Auditor wants everything inside Fusion |
Pathway A: HCM Extract (data-layer fix)
How it works:
- Switch from BIP to HCM Extract in Changes-Only mode
- HCM Extract maintains change-tracking metadata per extracted record
- Each run compares current values against tracked state
- Changes — including disappearances — surface as explicit events with old and new values
What you get:
- Native handling of date-tracked tables
- Native detection of record removals
- Full auditability inside Fusion, no extra infrastructure
Trade-off: output is XML, CSV, or custom eText. If your downstream contract is bespoke BIP output, expect some rework on the consumer side.
Pathway B: OIC orchestration (PaaS-layer fix)
How it works — four steps:
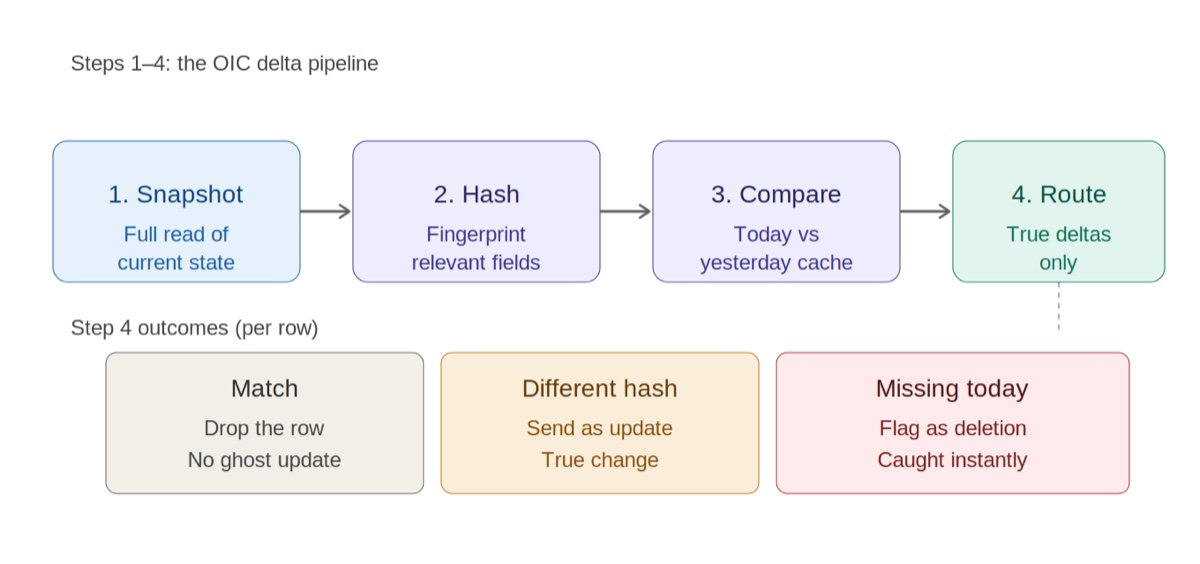
- Snapshot. OIC pulls a clean full read of current state via BIP or REST. No delta logic in the source query.
- Hash. OIC fingerprints each row using only the fields the downstream target cares about.
- Compare. Today’s fingerprints vs yesterday’s, stored in OCI Object Storage or an OIC lookup table.
- Route. Matches dropped. Different hashes sent as updates. Missing-today flagged as deletes — instantly and deterministically.
Important caveat: deletion detection only holds if the snapshot scope is stable across runs. Lock the WHERE clause, version the query.
Why BIP is fine here: BIP isn’t the problem when used as a simple read engine — only when forced to compute deltas. A scoped full-read query is exactly what BIP handles well.
The hardest part: the cutover
Re-architecting off LAST_UPDATE_DATE is straightforward as code. The hard part is historical reconciliation. Four questions to answer before flipping the switch:
- What’s the baseline, and who owns it? Reconcile to a fresh Fusion snapshot, accept downstream as the baseline, or do a one-time full reconciliation. Name the owner.
- What’s the parallel-run period? Two weeks minimum. A full payroll cycle is safer.
- What’s the rollback plan? If discrepancies surface mid-cutover, can you flip back cleanly?
- Who signs off? Tolerance, criteria, rollback trigger — all agreed before the first parallel run.
Code is the easy part. Reconciliation governance is where projects succeed or fail.
The bottom line
- Internal IT shouldn’t lose engineering cycles to phantom updates, missed records, and broken payroll feeds
- LAST_UPDATE_DATE looks cheap at design time and gets expensive forever after
- The fix is HCM Extract or OIC — not more SQL in BIP
At TekBlend, we re-architect legacy timestamp-based feeds onto HCM Extract or OIC-orchestrated delta pipelines, handle reconciliation governance, and hand the new architecture back to your BAU team with the runbook to operate it.
If your Fusion HCM integrations are showing any of the three symptoms above, we’d be glad to take a look.
Let’s look at your current Oracle environment and map out the cleanest, AI-driven path forward.